Modern computing has gone a long way. Elastic architectures have become commodities. With platforms like AWS and all its serverless offerings, you can build very reliable and very scalable systems. We learned to push static content very close to the end users thanks to the proliferation of CDNs. We then learned to run compute at the edge as well. One thing we still can’t really do effectively is push data to the edge.
What if I told you that you could use DNS? I didn’t come up with the idea. I’ve read about it here some time ago and when I had a problem that sounded like - “how do I get my data closer to the edge” - I remembered that blog post and I decided to try and do it.
An important caveat first. The problem I was solving is not a typical OLTP data problem. You are very unlikely to actually be able to replace a database with DNS using the approach I will present here. You can, however, deliver a fairly stable (and fairly small) dataset to the edge ang have low single to double digit milliseconds response time reading the data from anywhere in the world.
In a Nutshell
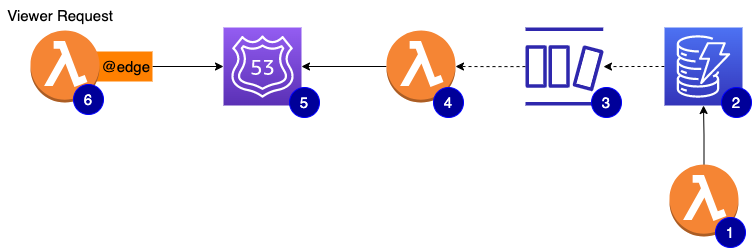
At a glance, the architecture looks like this:
#1 is a lambda function that is basically a CRUD API used by our developer portal to provision and manage your API access
#2 is the main DynamoDB table. The source of record for all API keys metadata
#3 is the stream enabled on the DynamoDB table to stream out any changes
#4 is a lambda function subscribed to the stream. Depending on the event captured, it will create, update, or delete a DNS replica using one TXT record per key
#5 the viewer-request can now dig DNS TXT record to quickly check if the API key is valid and has access to the requested API
Want to know more and look at the code? Please head over to our Anywhere Engineering blog and read the full article
It’s been a while since I published anything. More than three years! A lot of things happened since then. The most relevant to mention in the beginning of this post is that I have been super busy building a lot of cool tech with a very talented team here at EPAM Anywhere. We are doing full-stack Typescript with next.js and native AWS serverless services and can’t get enough of it. This experience has been challenging me to learn new things every day and I have a lot to share!
When you work with AWS, you will certainly use aws-sdk and APIs of different services. Need to send a message to an SQS queue? That’s an HTTP API call and you will use sdk. Need to update a document in DynamoDB? The same. Need to push a message to the Firehose? The same. Many of these APIs have their batch equivalents:
These batch APIs will throw if something fundamental is wrong. Say your auth is not good or you don’t have enough permissions or you don’t have the connectivity to the service. If the sdk connected successfully to the service but failed to perform some or all of the operations in your batch, the operation won’t throw. It will return an object that tells you which operations succeeded and which ones failed. The most likely reason to get partial failures is due to throttling. All of these APIs have soft and hard limits and sooner or later you will attempt to do more than AWS feels comfortable letting you get away with.
We learned it the hard way. It’s all documented, obviously, but things like this one are only obvious in hindsight. Let me show you a neat technique to batch safely:
/** * Perform batch write/delete to the DynamoDB. All records that failed will be retried up to five times with a backoff. * The method will throw if we failed to deliver the batch after the specified number of retries. Default is 5 * * This factory method returns a reusable function that you can use over and over again if you are sending batches to the same `table`. * * **NOTE** We are not checking any limits imposed by AWS/Dynamo. As of the time of this writing: * - 25 requests per batch * - max document size is 400Kb including attribute name lengths * - the total size of items written cannot exceed 16Mb (400x25 is less btw) * * @param db instantiated document client * @param table the name of the DynamoDB table to work with * @param retries how many times to retry. default is 5 * @param backoff backoff strategy that can be calculated based on the attempt number. the default is 100ms * attempt * @returns the reusable function that you call with your batch details */ exportconstdeliverBatchToDynamo = ({ db, table, retries = 5, backoff = attemptTimesOneHundredMs }: DynamoBatchDeliveryOptions) => (batch: DocumentClient.WriteRequests): Promise<void> => { const run = async (batch: DocumentClient.WriteRequests, attempt: number): Promise<void> => { if (attempt > retries) { thrownewError(`Failed to deliver batch after ${attempt} attempts`); }
Lambda@Edge allows you to run lambda functions in response to CloudFront events. In order to use a lambda function with CloudFront, you need to make sure that your function can assume edgelambda identity. I want to show you an easy way to do it with serverless.
Missing identity
As of right now, serverless framework has no native support for lambda@edge. There is a plugin though that allows you to associate your lambda functions with a CloudFront distribution’s behavior.
The plugin works great if you deploy and control both your lambda functions and its associations with the CloudFront distributions. You might, however, be deploying a global function that is to be used by different teams on different distributions. Here’s a good example - a function that supports redirecting / to /index.html deeper in the URL hierarchy than the site root.
Serverless allows you to define additional IAM role statements in iamRoleStatements block but doesn’t seem to have a shortcut for the iamRoleLambdaExecution. You can certainly configure your own custom IAM::Role but that’s a pretty involved excercise if all you want to achieve is this:
Easy way out
If you don’t define your own IAM::Role, serverless will create one for you. The easiest way to see how it looks is to run sls package, look inside your .serverless folder, and inspect the CloudFormation JSON that will orchestrate your deployment. Look for IamRoleLambdaExecution in the Resources group.
Serverless carries a template that it uses as a starting point to build the role definition. The good news is that serverless merges it into the list of other resources that you might have defined in your serverless.yml. Take a look at the code if you want to see how it does it.
The name of the roles seems to always default to IamRoleLambdaExecution (here and here). Knowing how lodash’s merge works, all we need to do now is to give our resources definition a little boost.
Recently I found myself integrating OAuth 2 into a React/node.js app. The web is full of blog posts and questions answered on how to do it, but I still had to scratch my head a few times to get everything right. This post is a simple step by step recipe on how to do it with Passport.
This wasn’t apparent to me from the beginning and from the simple examples that I looked at, but:
passport is designed to only facilitate the authentication process. In other words, the only route that should have passport middleware on it is the /login route where you would send your unauthenticated users to
Actually, you should also add the passport middleware to your callback route or just make /login your OAuth callback. That’s what I did. The OAuth strategy looks at ?code= in the URL to decide whether to initiate the authentication sequence or process the callback:
To be able to do passport.authenticate('oauth2', {...}) as I showed in step 4, you should set up passport with the OAuth 2 strategy first:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
constOAuth2Strategy = require('passport-oauth2');
consttokenToProfile = async () => {} // <-- I will explain in step 9
const strategy = newOAuth2Strategy({ state: true, authorizationURL: process.env.AUTH_AUTHORIZATION_URL, tokenURL: process.env.AUTH_TOKEN_URL, clientID: process.env.AUTH_CLIENT_ID, clientSecret: process.env.AUTH_CLIENT_SECRET, callbackURL: process.env.AUTH_CALLBACK_URL, passReqToCallback: true// <-- I will explain in step 9 }, tokenToProfile);
passport.use(strategy);
Step 7. De/Serialize user
In order not to run the authentication sequence on every request, you would typically store the authenticated user ID in the session and then trust it for as long as the session is active. You need to implement serializeUser and deserializeUser to do it. Passport doesn’t do it automatically:
passport.serializeUser((user, done) => { // The user object in the arguments is the result of your authentication process // (see step 9)
done(null, user);
// If your user object is large or has transient state, // you may want to only store the user id in the session instead:
// done(null, user.user_id) });
passport.deserializeUser(async (user, done) => { // The user object in the arguments is what you have stored in the session
// If you stored the entire user object when you serialized it to session, // you can skip re-quering your user store on every request
user = awaitUser.getUserByID(user.user_id);
done(null, user); });
Step 8. Tokens
OAuth 2 can send back access_token and it can also send the id_token. The latter is always a JWT token and the former is typically an opaque string.
Sometimes all you need is the access_token that you pass on to the back-end APIs. I, however, needed to authenticate the user and match the user’s identity with the application’s user record.
Two options:
Use the /userinfo endpoint with the access_token to retrieve the profile from your identity provider
Ask for the id_token and get profile attributes from there. To receive the id_token in the callback, you need to add scope=openid to your authorization request. If you need user’s email or additional attributes like name, for example, you will need to ask for more scopes (scope=openid email or scope=openid profile).
OAuth 2.0 is not an authentication protocol, apparently. Read the User Authentication article on oauth.net if you want to learn more. The id_token, claims, scopes, and /userinfo are all part of OpenID Connect.
Step 9. Retrieve Profile
When we set up the OAuth 2 strategy in step 6, we had to supply a tokenToProfile callback. If you read the documentation, you will see that it has the following signature:
1 2 3
function (accessToken, refreshToken, profile, cb) { // Note: no id_token passed in the arguments }
Don’t be surprised to always receive an empty object in profile:
OAuth 2 strategy for passport does not implement retrieval of the user profile
The latter requires you to not only ask for the id_token from your identity provider using scope=openid, but to also have it exposed to you by the OAuth 2 strategy in passport. To do so, you need to set passReqToCallback to true when you instantiate the strategy (we did in step 6), and then you can use a different signatue for your callback:
The easiest and the most effective way to logout a user is to destroy the session:
1 2 3
router.get('/logout', function (req, res) { req.session.destroy(() => res.redirect('/')); });
Step 11 (Bonus). Spoof Authentication
If you have gotten this far, I have a bonus step for you. I found it very helpful to be able to spoof authentication in local environment for development and testing.
First, the environment variable in my .env file to signal that the auth should be bypassed and to tell the app what user to run on behalf of:
Last night I finally got a chance to publish the remaining setup scripts for my E-Commerce Chatbot. A few days ago, I added the script to load up products and variants into Azure Search and now also the catalog and historical transactions for Azure Recommendations. I basically had to script what I originally did as a one-off with curl.
Training the recommender model takes time and when you create a new recommendation build, it won’t be ready right away. I wanted my script to wait and keep polling the API until the training has finished. The whole script is basically a serious of asynchronous HTTP requests so I wired it all up as a chain of promises:
It’s basically a recursive promise. The function in the main then() will return a promise that will always resolve unless there’s an error, but the key is in what it will resolve with and how it runs. The function that the returned promise is wrapped around schedules itself via setTimeout() and exits the stack frame. Then, when the response is received, it will either resolve and signal that the training has complete, or it will resolve with another promise that will recursively repeat this process again. That another promise will basically insert itself into the main then chain and it will keep waiting until it resolves. Vicious circle.
It worked nicely and I even factored out the repeater so that my code looked like this:
It’s not even funny! The code is so boring now, boring and simple. Just like it should be. No need to be clever and I bet I will know exactly what it’s doing and why when I look at it a year later.
A few weeks ago I found myself building a simple app, a prototype actually. It has a nice interface to request that a certain job (or multiple) be executed in the background. It also provides real-time updates about those jobs. Nothing that you can’t do with JavaScript. I quickly settled on a node.js back-end with a React front-end and a socket.io channel in between.
This post is about how I set up my solution and my dev environment to nicely bundle my client and my server together to make everything work smoothly locally (including the compound end-to-end debugging) as well as to be ready for production deployment to heroku.
The first three things that I did after I created the solution folder were:
1 2 3
& cd solution && npm init $ create-react-app client $ mkdir server && cd server && npm init
In development, I would like my client to start up using react-scripts with webpack server on :3000 with hot reloading and other awesomeness. In production, however, my server will be serving up all front-end assets. And it will run on a different port locally when executed side by side with the webpack server. From server/app.js:
Now when I do npm run debug in the solution root, I get two processes spun up - one runs the server/app.js on :3001 and the other one runs the client on :3000. I also run server in debug mode and this will come handy when we get to setting up local debugging.
By the way, I used debug and not start command because I need npm start to be the way heroku launches this setup in production where server handles it all:
I also need heroku to install all dependencies and build the front-end every time I push new version up. That’s one more npm command in the solution level package.json:
1 2 3 4 5
"scripts": { "debug": "...", "start": "...", "postinstall": "cd server && npm install && cd ../client && npm install && npm run build" }
The client expects socket.io to be accessible on the /api endpoint from the same server. From the App.js:
Easy in production setting where there is only one server. This is where proxy comes in to aid the development setup. We need to tell the webpack dev server to proxy everything it can’t handle to the server over at :3001. Need to add one little line to the client/pacakge.json:
1 2 3
{ "proxy": "http://localhost:3001/" }
Last but not least, I would really like to be able to debug both client and server in one place. Visual Studio Code supports compound debugging since late last year. Here’s my launch configuration:
You will need the Debugger for Chrome extension. Now you can npm run debug and then F5 to attach to both processes.
Nirvana.
Anthony Accomazzo’s post - Using create-react-app with a server - made it very easy for me to set it all up. I am very happy to share it a little further with a thin layer of heroku and VS code debugging.
I have blogged about sentiment detection and relaxed prompts before. I have recently put the two together and came up with a good recipe for handling prompts. Let me show you why I needed it and how I dealt with it.
Curve Ball
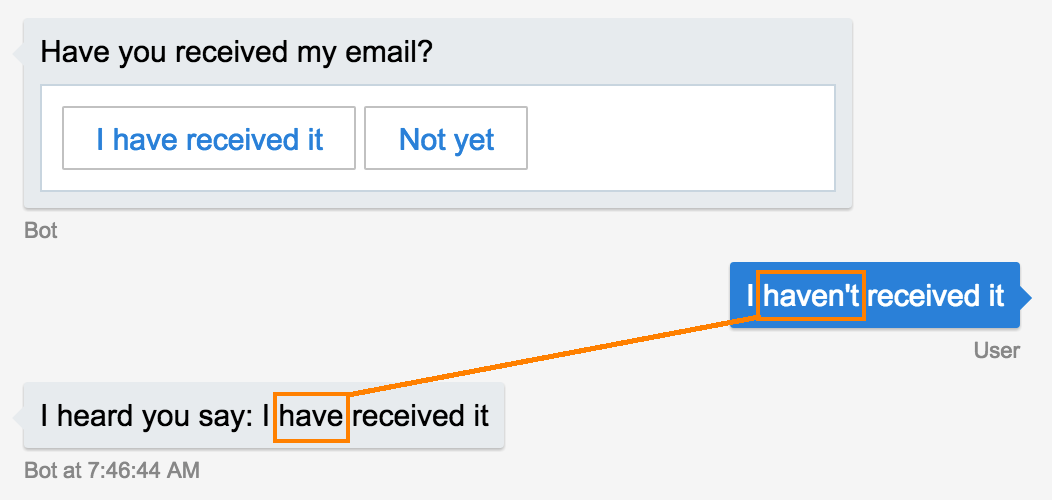
The bot framework can throw you a curve ball if you’re not careful selecting your prompts choices:
It is actually trying to be smart. The bot is not sure but believes with 61% confidence that the user said I have received it. And a clear opposite to the positive option - I have not received it - would match with even stronger 83% score. WAT.
For simple yes/no choices, the bot will try a regex:
// [excerpt from EntityRecognizer.ts] // value - one of the choices given to the Prompts // utterance - the user's response // both are trimmed and lower cased.
var tokens = utterance.split(' ');
if (value.indexOf(utterance) >= 0) { score = utterance.length / value.length;
61% is the result of computing 'Ireceivedit'.length/'I have received it'.length. The alternative I have not received it gives us an even better score as more tokens find a match.
Tip #1: Spend some time thinking about how you formulate your choices not to get trapped by the fuzzy match logic.
Ambiguity
Since I built my first chatbot last year, I often find myself consulting EPAM‘s clients on the technology and the approach, and go as far as helping their teams get off the ground building one.
My go-to technique to bootstrap the conversation is to ask a client to document their imaginary conversation with the bot as if it existed. I can get a lot from this simple exercise. I can recommend a proper delivery channel. It will help decide if they need a custom built NLU service or can get by with LUIS or API.ai. I will also use their dialogue to educate them about what’s easy with the commoditized AI and what’s not. Asking the bot to do three things at once, for example, may sound very natural, but will likely be a lot harder to handle.
I also try to disambiguate the prompts:
Bot >> Did you receive my email? [yes/no]
User >> no
Bot >> Did you check your spam folder?
I would instead have the bot say:
Bot >> Please check your spam folder. Did you find the email there? [yes/no]
This way the bot has no problem understanding what the positive yes and the negative no mean.
Tip #2. If the bot needs to ask a yes/no question, make it a yes/no question. Unless, of course, you want to spend time building smarter brains for your bot
Another example:
[IT Support, locked account scenario]
Bot >> You can either wait 15 minutes and try again
Bot >> or you can reset your password to unlock your account now
Bot >> What would you like to do?
You can give the user two mutually exclusive options and lock the prompt, but if you are like me and prefer to keep the prompts more open and relaxed, you might want to change the bot’s prompt to:
Bot >> You can either wait 15 minutes and try again
Bot >> or you can reset your password to unlock your account now
Bot >> Would you like to reset your password? [yes/no]
Last example:
[end of the dialog]
Bot >> Great! Anything else I can help you with?
It’s a very natural prompt, but I suggest you don’t let your bot ask it this way. Not unless you’re ready to handle an arbitrary reply. Instead, have the bot say something like:
Bot >> Great! I am glad I was able to help
Tip 3. Don’t solicit feedback from your user that you are not equipped to handle.
Sentiment
If you follow the first three tips, you are very likely to have more yes/no prompts in your dialogs than other binary questions. EntityRecognizer does a good job with a simple regex but you may want to dial it up a notch with sentiment detection.
The idea is simple. Prompt the user with a yes/no question but do it in a relaxed manner. Let the user answer with whatever they feel like if they don’t use the buttons. Then, let the Bot Framework try to understand if it was a yes or a no. If not successful, turn to sentiment detection and treat a positive expression as a yes and a negative as a no. And finally, if sentiment detection comes back inconclusive, re-prompt the user and this time lock the choices to yes/no.
// [module sentiment.js] // github link to the full implementation is provided below
module.exports = { detect: function (text, language = 'en', threshold = 0.05) { },
confirm: function (question, reprompt) { return [ // Step 1. Relaxed yes/no prompt via Prompts.confirm (session, args, next) => { builder.Prompts.confirm(session, question, { listStyle: builder.ListStyle.button, maxRetries: 0// <-- no re-prompt }) }, // Step 2. Try Sentiment detection as an alternative (session, args, next) => { if (args && typeof(args.response) !== 'undefined') { // The bot framework recognized a 'yes' or a 'no' next(args); } else { // Turn to sentiment detection this.detect(session.message.text) .then(response =>next(response)) .catch(error => { console.error(error); next(); }); } }, // Step 3. Re-prompt if needed (session, args, next) => { if (args && typeof(args.response) !== 'undefined') { // We have a yes/no next(args); } else { // Inconclusive. Need to re-prompt. reprompt = reprompt || 'I am sorry, I did not understand what you meant. ' + 'See if you can use the buttons ' + 'or reply with a simple \'yes\' or \'no\'. ';
session.send(reprompt);
builder.Prompts.confirm(session, question, { listStyle: builder.ListStyle.button // <-- maxRetries is not set, re-prompt indefinitely }) } } ] } };
And now we can easily use it in our dialogs thanks to the spread syntax:
bot.dialog('/addToCart', [ function (session, args, next) { // ... },
// <-- using the macro we've just created ...sentiment.confirm('Would you like to see a few recommendations?'),
// <-- next waterfall step will receive a proper yes/no function (session, args, next) { if (!args.response) { session.endDialog('Alright'); } else { showRecommendations(session); } } ]);
I am using this technique in my e-commerce chatbot example and here’s a link to the full sentiment.js
Tip #4: Make your prompts handling smarter with sentiment detection but be ready to lock the user into a yes/no decision if sentiment detection comes back inconclusive.
A bot that one of our teams is working on has the following functional requirement:
Dialog reaches a point where chatbot is no longer able to help. At this point, a transcript of the conversation will be sent to a mailbox.
Capturing a transcript requires that we keep track of all messages that are sent and received by the bot. The framework only keeps track of the conversations’ current dialogs stack. I already showed you guys how to build a simple history engine and give the bot the breadcrumbs of the entire conversation. Let’s see how we can record a transcript.
Option 1. Events (first attempt)
UniversalBot extends the node.js’s EventEmitter and will produce a number of events as it processes incoming and outgoing messages. We can subscribe to send and receive, for example:
1 2 3 4 5 6 7 8 9 10 11
bot.on('send', function(event) { if (event.type === 'message') { // ToDo: record in the transcript journal } });
bot.on('receive', function(event) { if (event.type === 'message') { // ToDo: record in the transcript journal } });
There’s a little caveat that I want to bring up before I show you how to get to the conversation’s session in the event handler.
send and receive are emitted before the bot runs through the middleware stack. In general, an exception in one of the middleware components should not break the chain, but if you want to only capture messages that were actually dispatched to the user, you would subscribe to outgoing that files after the middleware chain.
// NOTE 1: I will explain this line in details and show you // that it doesn't actually do what you might think it does session.save(); };
bot.on('incoming', function (message) { if (message.type === 'message') {
// NOTE 2: loadSession() warrants an in depth explanation as well bot.loadSession(message.address, (error, session) => { transcript(session, 'incoming', message.text); }); } });
bot.on('outgoing', function (message) { // ... (same as incoming, will refactor later) });
NOTE 1. session.save()
It’s very important to understand how the bot handles the session data. The default mechanism is MemoryBotStorage that stores everything in memory and works synchronously. Your bot would default to it if you used the ConsoleConnector. You are a lot more likely to use the ChatConnector that comes with external persistence implementation. It will be reading and saving data asynchronously. Please also note that everything you put on session (e.g. session.userData) is JSON serialized for storage. Don’t try keeping callback functions around on the session.dialogData, for example.
The next very important thing to understand is that session.save() is asynchronous as well. It’s actually worse. It’s delayed via setTimeout(). The delay is configurable via autoBatchDelay and defaults to 250 milliseconds. The bot will auto-save all session data as part of sending the messages out to the user which it does in batches. The delay is built into the batching logic to ensure the bot doesn’t spend extra I/O cycles when it feels like sending multiple messages. Calling session.save() just triggers the next batch.
You can remove the delay:
1 2 3 4
const bot = new builder.UniversalBot(connector, { persistConversationData: true, autoBatchDelay: 0// <-- the default is 250 });
The batching will still be asynchronous though. You can also bypass the batching altogether and instead of session.save() call session.options.onSave() directly, but you can’t work around the asynchronous nature of how the data is saved by the ChatConnector.
NOTE 2. bot.loadSession()
This method is not part of the documented public API and there’s probably a good reason for it. The bot framework doesn’t keep the sessions around. Session objects are created on demand and discarded by the GC when the request/response cycle is over. In order to create a new session object, the bot needs to load and deserialize the session data which as you just have learned happens asynchronously.
If you run the code I showed you, you will only see the outgoing messages on the transcript.
The incoming messages are swallowed and overwritten by the asynchronous and delayed processing.
Option 1. Events (second attempt)
There’s one event in the incoming message processing pipeline that is different from all others - routing. An event handler for routing is given a session object that the bot framework has just created to pass on to the selected dialog. We can transcript without having to load our own session instance:
1 2 3
bot.on('routing', function (session) { transcript(session, 'incoming', session.message.text); });
The routing event is the last in the chain of receive -> (middleware) -> incoming -> routing.
There is no equivalent to routing on the way out though. No event in send -> (middleware) -> outgoing chain is given the session object. There is a good reason why. Sending the messages out happens after the bot finished saving the session data.
While it’s sad that we don’t have an equivalent of routing in the outbound pipeline, knowing that session data is complete prior to bot framework dispatching the messages out makes me feel good about re-saving it. We don’t risk overwriting anything important like call stack or other session data.
const transcript = function (session, direction, message) { session.privateConversationData.transcript = session.privateConversationData.transcript || []; session.privateConversationData.transcript.push({ direction, message, timestamp: newDate().toUTCString() }); // no need to explicitely save() for the incoming if (direction === 'outgoing') { session.save(); } };
bot.on('routing', function (session) { transcript(session, 'incoming', session.message.text); });
bot.on('outgoing', function (message) { if (message.type === 'message') { bot.loadSession(message.address, (error, session) => { transcript(session, 'outgoing', message.text); }); } });
This time it works as expected but is not free of side effects. The bot.loadSession() on the way out is still asynchronous and prone to interleaving. If your bot starts sending multiple messages and especially doing so asynchronously in response to receiving external data via a Promise, for example, you may find yourself not capturing all of it.
Option 2. Middleware
Another way of intercepting incoming and outgoing messages is to inject a custom middleware. The middleware is called in between receive and incoming, and also in between send and outgoing:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
bot.use({ send: function (message, next) { if (message.type === 'message') { // ToDo: record in the transcript journal } next(); // <-- I will explain in NOTE 3 below }, receive: function (message, next) { if (message.type === 'message') { // ToDo: record in the transcript journal } next(); // <-- I will explain in NOTE 3 below } });
NOTE 3. next()
Middleware that you inject via bot.use() form a stack that is processed synchronously and in order. The bot framework does it via a recursive function that self-invokes. Every invocation notifies the next middleware in the chain and will eventually call the main processing callback. This is a nice way to keep running down the list even when one errors out as it will self-invoke in a catch block. I suggest that you guys take a closer look at UniversalBot.prototype.eventMiddleware if you’re interested. So if we don’t call next(), the chain will not continue and the bot will never receive the message.
We can use this feature to our advantage. If we chain next() onto the direct call to session.options.onSave(), we can ensure that the chain continues after the successful journaling of the transcript. No chance to have them all interleave and overwrite one another, though it probably takes longer before it gets to the user:
You can also combine the two techniques and use routing event for incoming messages and only use send middleware to capture the outgoing traffic. Just make sure that you don’t do session.save() for the incoming. Here’s a gist.
Option 3. External Joural
I don’t know how stable is session.options.onSave() and bot.loadSession(). Neither one is part of the official public API so use at your own risk.
You can also roll your own transcript service and safely call it asynchronously from the send and receive event handlers. What I like about using session.privateConversationData is that I need no custom infrastructure and can easily discard the transcripts if I don’t use them. The bot framework will take care of it for me.
It would be nice though if bot framework gave me a routing-like event for the outbound pipeline that would fire before saving of the data. This way I would be able to nicely record the transcript without disrupting the flow of things, and wouldn’t risk relying on internal implementation detail that can easily go away in the next version.
This post continues the smarter conversations series and today I would like to show you how to keep track of the conversation flow and help your bot remember and reason about it. Previously, in part 1, I showed how to add sentiment detection to your bot and in part 2 I explored ways to keep your dialogs more open.
Breadcrumbs
In part 1 I used the following dialog to illustrate why you might want to be able to detect expressed sentiment:
User >> I’m looking for screws used for printer assembly
Bot >> Sure, I’m happy to help you.
Bot >> Is the base material metal or plastic?
User >> metal
Bot >> [lists a few recommendations]
Bot >> [mentions screws that can form their own threads]
User >> Great! I think that's what I need
Bot >> [recommends more information and an installation video]
The highlighted phrase is not an expression of a new intent, not an answer to the bot’s prompt. It’s a positive emotional reaction to the perfectly timed recommendation about thread forming screws. We were able to capture it and present to our bot as an intent:
Unlike other intents, however, the Affirmation intent can’t be fulfilled without knowing what came before it. Wouldn’t it be great if the bot had access to the conversation’s breadcrumbs? If it could reason about what was talked about before?
History Engine
While the bot framework doesn’t keep the history of triggered intents and actions beyond the active dialog stack, it’s not hard to build a simple history engine that would take care of it.
Probably the easiest way to do it is via the onSelectRoute hook:
1 2 3 4 5 6 7 8 9 10 11 12 13
// ... const bot = new builder.UniversalBot(connector);
// Don't forget to call the default processor. // While the "on" syntax suggests that it's an event handler, // the onSelectRoute actually replaces the default logic with yours this.defaultSelectRoute(...arguments); });
The route.routeData.action is the name of the dialog that is about to be triggered. Here’s how your bot would use it:
const affirmations = { '*:productLookup': (session, args, next) => { // handle positive reaction right after product lookup }, '*:howToOrder': (session, args, next) => { // handle positive reaction right after ordering tips } }
bot.dialog('affirmation', [ function (session, args, next) { const history = session.privateConversationData.history || [];
// The last step in the history is the one currently being executed const affirmationFor = history[history.length - 2]; const action = affirmations[affirmationFor]; if (!action) { session.endDialog(); } else { action(session, args, next); } } ]).triggerAction({ matches: 'Affirmation', onSelectAction: function (session, args, next) { // keep the interrupted dialog on the stack session.beginDialog(args.action, args); } });
It’s important to note that if you are using the IntentDialog, you won’t see onSelectRoute triggered for your intent.matches(). This is because the matching is handled by the dialog, not the routing system. I stopped using the IntentDialog bound to / in favor or recently added global recognizers and triggers and will soon upgrade my ecommerce bot.
Relaxed Prompt
I wanted to share one more technique that I recently discovered and started using a lot to keep my prompts more open, more relaxed.
In the product selection dialog, for example, you may find yourself giving your user a set of options to choose from and also an option to forego the selection:
...
Bot >> Would you like to look at one particular brand?
Bot >> [lists a few brand choices as buttons]
User >> No, thank you
The answer no, thank you is not one of the brand options and I wouldn’t render it as such either. I would like the bot to accept one of the options given and consider everything else not picked up by any other recognizer as a no, thank you answer.
All we need to do, apparently, is to make sure the bot doesn’t reprompt if it receives a wrong answer and is ready for an alternative response:
bot.dialog('brands', [ function (session, args, next) { // products that match previous user's selections const products = session.privateConversationData.products; // distinct list of brands const brands = [...newSet(products.map(p => p.brand))];
// will come in handy when processing the response session.dialogData.brands = brands; session.save();
builder.Prompts.choice(session, 'Would you like to look at one particular brand?', brands, { listStyle: builder.ListStyle.button, maxRetries: 0// <-- No re-prompt })); }, function (session, args, next) { // either one of the options provided, or something else const reply = (args.response && arg.response.entity) || session.message.text;
const brands = session.dialogData.brands;
if (brands.includes(reply)) { // continue with a list filtered down by the selected brand } else { // "no, thank you". continue with a full list } } ]);
That’s it for today. Next time I will show you how to keep a full history of a conversation and be ready to send a transcript to the customer support agent when the bot gets stuck.
My go-to NLU service for all the bot prototypes that I build with Microsoft Bot Framework is LUIS. This time, however, I needed to build a bot that would speak a language that LUIS doesn’t understand yet. I needed my bot to speak Russian.
It probably took me under ten minutes to sign up for api.ai, orient myself with the tool, and train an agent that would understand one intent and extract one entity out of it. Their web interface is very slick, very intuitive to navigate.
I didn’t set up any events or actions, didn’t configure webhook fulfillments, and didn’t use the one-click integrations. All I needed my api.ai agent to do was to recognize the intent and extract the entity. Everything else in my case is done by the Bot Framework.
I could now send the request with my user’s utterance to api.ai and receive a JSON payload back: