A quick blog post about Content Testing feature of Sitecore and its unfriendliness towards Context.Site
I went through a few content testing scenarios recently and one thing really puzzled me: Content Testing dialogs stumble upon Context.Site.
Reference Storefront
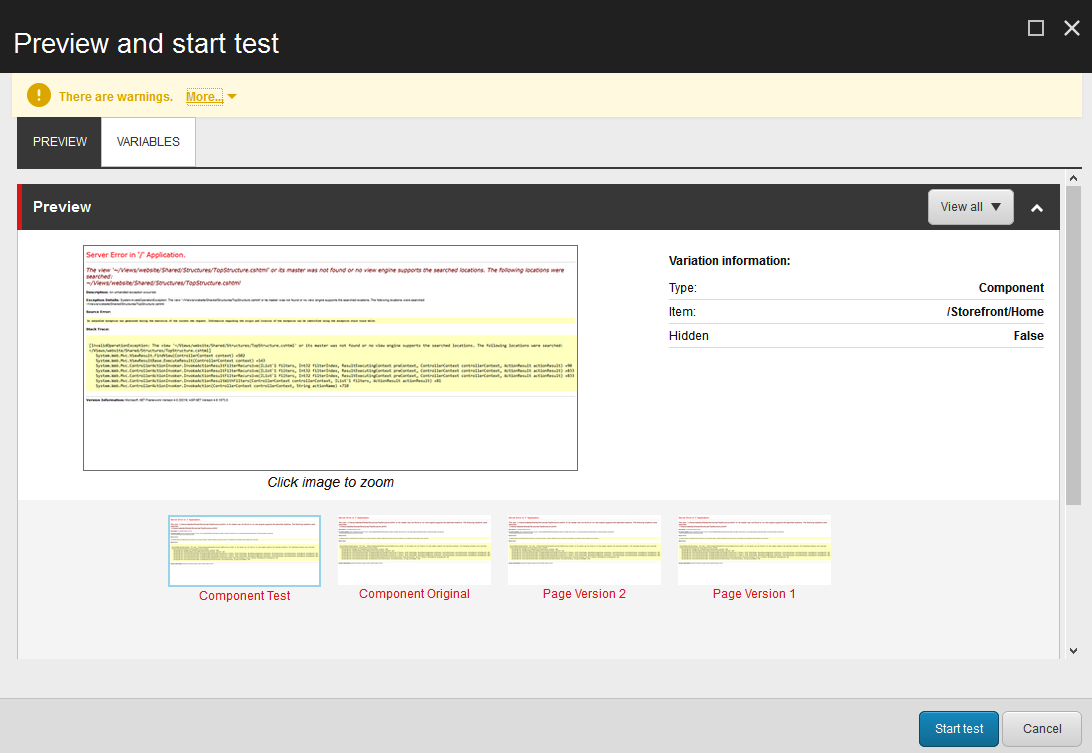
If you try to set up a test in the Sitecore Commerce reference storefront and send the page through the workflow, here’s how the variants screenshots will look like:
The base controller is using Context.Site for view path resolution:
1 2 3 4 5 6 7 8 9 10 11 12 13
protectedstringGetRenderingView(string renderingViewName = null) { /* ShopName is a property on the CommerceStorefront object that is represented by an item at Context.Site.RootPath + Context.Site.StartItem */ var shopName = StorefrontManager.CurrentStorefront.ShopName; // ... conststring RenderingViewPathFormatString = "~/Views/{0}/{1}/{2}.cshtml"; // ... returnstring.Format(RenderingViewPathFormatString, shopName, "Shared", renderingViewName); }
And it won’t find anything in the shell site:
1 2 3 4 5 6 7 8 9
Nested Exception
Exception: System.InvalidOperationException Message: The view '~/Views/shell/Shared/Structures/TopStructure.cshtml' or its master was not found or no view engine supports the searched locations. The following locations were searched: ~/Views/shell/Shared/Structures/TopStructure.cshtml Source: System.Web.Mvc at System.Web.Mvc.ViewResult.FindView(ControllerContext context) at System.Web.Mvc.ViewResultBase.ExecuteResult(ControllerContext context) ...
Habitat
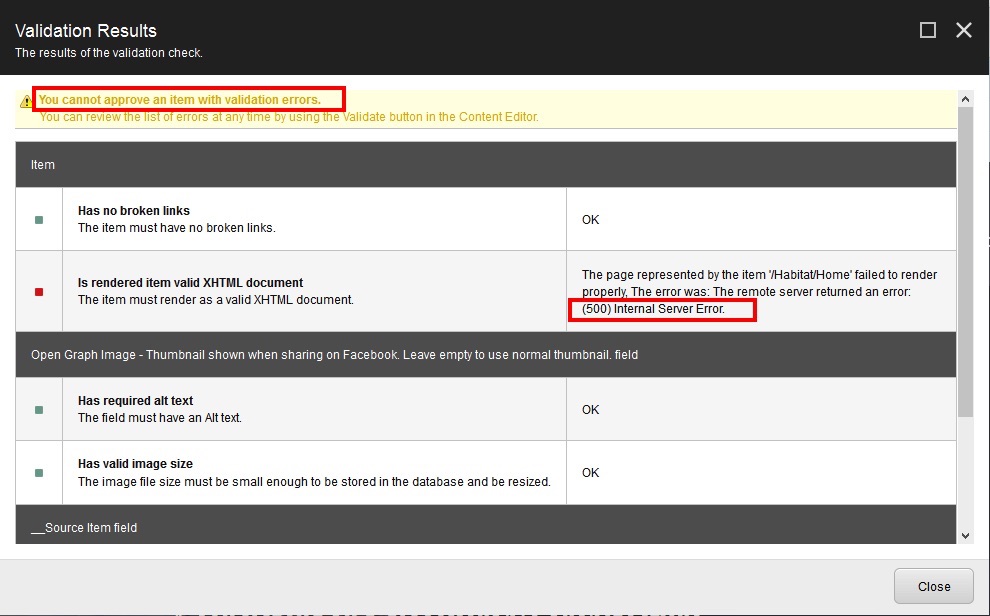
Trying the same workflow with test in Habitat stumbles upon the validation step:
Here the Context.Site is being used for custom dictionary functionality:
1 2 3 4 5 6 7 8 9 10 11 12
private Item GetDictionaryRoot(SiteContext site) { var dictionaryPath = site.Properties["dictionaryPath"]; if (dictionaryPath == null) { thrownew ConfigurationErrorsException("No dictionaryPath was specified on the <site> definition."); }
// ... return rootItem; }
And it also errors out in shell:
1 2 3 4 5 6 7 8 9
Nested Exception
Exception: System.Configuration.ConfigurationErrorsException Message: 'No dictionaryPath was specified on the <site> definition'. Source: Sitecore.Foundation.Dictionary at Sitecore.Foundation.Dictionary.Repositories.DictionaryRepository.GetDictionaryRoot(SiteContext site) at Sitecore.Foundation.Dictionary.Repositories.DictionaryRepository.Get(SiteContext site) at Sitecore.Foundation.Dictionary.Repositories.DictionaryRepository.get_Current() ...
Alistair Deneys explained that Content Testing needs to run screenshot generation in context of shell to render unpublished content of different versions.
Content Testing needs to quickly learn how to do everything it needs in the context of the current site while getting everything from the master database.
While you probably shouldn’t use Context.Site for view path resolution - we now have official support for MVC areas, and probably shouldn’t use custom dictionary implementation - here’s my blog post on how to make standard dictionary items editable in Experience Editor, you should be allowed to use Context.Site in your page rendering logic if you need it.
Name __Display name Category ---- -------------- -------- 22565422120 Gift Card Departments AW007-08 Black Diamond Quicksilver II Carabiners AW009-08 Black Diamond Quicksilver II SaleItems AW013-08 Petzl Spirit Adventure Works Catalog ...
Adding Features
Features need to be exported in a special format. Different products in a given catalog may have different features and even have different number of them. Azure solves this by requiring features as a comma separated list of name value pairs:
PSObject is a dynamic type that you can modify on the fly. First, I extracted a collection of features into a new Features property. Then I applied features to become new properties on the product object. CSV export will be able to pick it up transparently. I hope.
CSV
It should now be easy to export the list as CSV. There’s a caveat though.
Both ConvertTo-CSV and Export-CSV will happily export the list for you but will normalize every record to the common set of fields.
You won’t see the features in the list. Here’s a trick to get every product in the export have its own features:
Instead of piping the entire set to the ConvertTo-CSV, I basically processed the list one by one in the foreach loop. I also removed the type info and the CSV headers. Azure doesn’t need labels anyway. Works like a charm!
There’s one more thing that I needed to do for Azure Recommendations API to absorb the catalog. As you could tell, the catalog format is not exactly CSV. Every line can have different number of fields basically. Neither does Azure backend use CSV parsing to read it.
The double quotes in the export above were taken literally. Azure would think that the SKU # is "AW007-08", for example. And then the commas in the descriptions where messing up the parsing as well. My next post will be about the Recommendations API itself and I will write more about it, but here’s the final version that produces a clean catalog export ready to go:
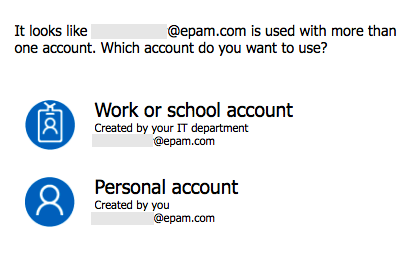
I was playing with Azure Cognitive Services and figured that I would switch to my @epam.com account for the next prototype. I needed to re-sign-up. This is my story.
Login
Microsoft’s live.com OAuth can integrate with your ADFS for a single sign-on experience:
I opted in for my work account, authenticated, and went ahead to enable the services I needed.
Verification
To enable Cognitive Service APIs on this account I needed to activate my Azure subscription. Microsoft will challenge your identity twice.
First, it’s the code verification that you can do by sending yourself a text. My form was pre-populated with the Belarus country code (+375). I quickly dismissed it as probably an old attribute on my AD profile. You see, I lived in Minsk (Belarus) before I moved to the states a good while ago but not every enterprise system got the memo. No big deal. Typed in my cell phone and got the activation code.
Then it’s the identify verification by card:
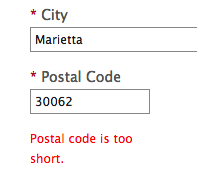
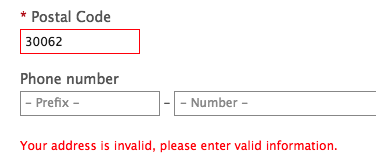
My postal code is again pre-populated with the one from the past. This time, however, I wasn’t able to use my current address:
What do you do when an online form tries to outsmart you? I, personally, try to outsmart it back:
Guess what, Microsoft engineers are very diligent. The validation also runs server-side and the form comes back with an error:
Sigh… My US street address and the city of Marietta were gladly accepted. It’s the postal code format and length validation that failed. Why so serious? A better solution would probably be to ask for a country as part of the address form and validate against it. Or maybe trust the SSO challenge that I went through when logging in and just collect my card?
Anyway. I guess I will keep using my personal account with Azure for now and will wait for out IT to find the field in my profile that ties me to my home country.
I have used Cognitive Services from Microsoft (part 1) and IBM Watson Services (part 2) to read my avatar image. There are two more APIs that I would like to put to the test - Google Cloud Vision API and Clarifai.
Google Cloud Vision
I already had a developer account. To use the Cloud Vision API I only had to enable it in the console and generate myself a browser key. When you sign up, Google asks for your credit card but they promise not to charge it without your permission. They also give you $300 in free trial credit and 60 days to use it.
The API itself is clearly designed for extensibility.
It’s a single endpoint that can do different things based on your request. An image can either be sent as a binary data or as a URL to a Google Storage Bucket. You can send multiple images at once and every image request can ask for different type of analysis. You can also ask for more than one type of analysis for a given image.
Google can easily add new features without adding new APIs or changing the endpoint’s semantics. Take a look:
A man who definitely cares about his hair, right? :) I am not sure where the sports and athlete bits came from. I also wonder if I would get more tags (like a microphone, for example) if I could ask for features with lower scores. The API doesn’t seem to allow me to lower the threshold. I asked for ten results but got only six back.
The face detection sent down a very elaborate data structure with coordinates of all the little facial features. Things like left eye, right eye, eyebrows, nose tip, and a whole lot more. The only thing is … you can’t see the left side of my face on my avatar.
Google also tries to detect emotions. Of all that it can see - anger, joy, sorrow, surprise - none came back with anything but VERY_UNLIKELY. You can also test an image for explicit content. Same VERY_UNLIKELY for my avatar.
Very pleasant experience but I honestly expected a little more from Google’s Vision API.
I expected more because I know Google does all kinds of crazy things with deep learning in their labs. With images as of two years go and very recently with video. Maybe as those models mature, the Cloud Vision will support more features? Time will tell.
Clarifai
The easiest setup experience by far!
I was ready to go in just a few seconds, no kidding! And it also felt like the fastest response from all the APIs I tried. Very easy and intuitive to use as well:
This is actually very close! Good feature detection with various plausible scenarios spelled out based on that. I would only question the absolute confidence in music and singer :) What about a… conference and a speaker?
Clarifai has another very interesting endpoint - Feedback. I haven’t used it but it seems that you can submit your own labels back to Clarifai and help them train and fine-tune the model. It won’t be your own classifier like Watson does. Feedback seems to be a crowdsourcing mechanism to train their main shared model(s). I only wonder how it will work without you having to specify the area of the image that each new label is attached to. In case of my avatar, conference and speaker would attach to the whole image. What about more involved images? Maybe I am missing something…
There’s a lot more computer vision APIs out there. Some are more generic and some a geared towards more specialized tasks like visual product search or logo recognition. Go give it a try!
It’s fascinating what kinds of things are just one HTTP request away.
In part 1 of this blog series I had Microsoft’s Computer Vision analyze my avatar. Today I would like to ask Mr. Watson from IBM to do the same.
Setup
Same as last time, modern JavaScript and a modern browser.
Getting started with Watson APIs takes a few more steps but it’s still very intuitive. Once you’re all set with Bluemix account, you can provision the service you need and let it see your images.
API
IBM had two vision APIs. AlchemyVision has been recently merged with the Visual Recognition. If you use the original Alchemy endpoint, you will receive the following notice in the JSON response: THIS API FUNCTIONALITY IS DEPRECATED AND HAS BEEN MIGRATED TO WATSON VISUAL RECOGNITION. THIS API WILL BE DISABLED ON MAY 19, 2017.
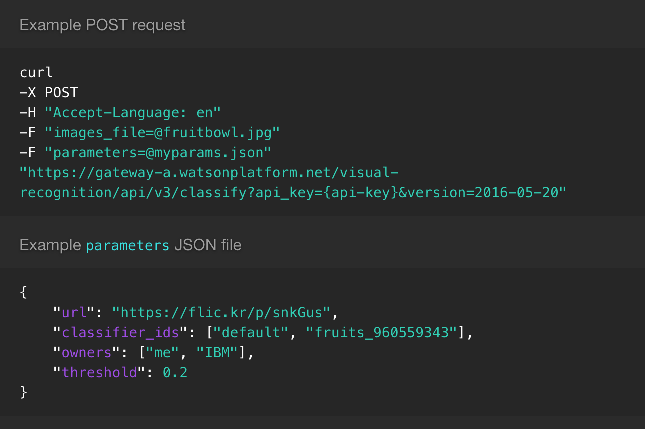
The new unified API is a little weird. Similar to the computer vision from Microsoft, it can process binary images or can go after an image by its URL. Both need to be submitted as multipart/form-data though. Here’s an exampel from the API reference:
It’s the first HTTP API that I’ve seen where I would be asked to supply JSON parameters as a file upload. You guys? Anyway. Thanks to the Blob object I can emulate multipart file upload directly from JavaScript.
Another puzzling bit is the version parameter. There’s a v3 in the URL but you also need to supply a release date of the version of the API you want to use. Trying without it gives me 400 Bad Request. There’s no version on the service instance that I provisioned so I just rolled with what’s in the API reference. It worked.
I also couldn’t use fetch with this endpoint. This time it’s not on Watson though. My browser would happily send Accept-Encoding with gzip in it and IBM’s nginx would gladly zip up the response. Chrome dev tools can deal with it but fetch apparently can’t. I get SyntaxError: Unexpected end of input at SyntaxError (native) when calling .json() on the response object.
Yep. That’s it. That’s all the built-in classifier could tell me. You can train your own classifier(s) but they all appear to be basic. No feature detection that would allow to describe images. I tried to see all classes in the default classifier but the discovery endpoint returns 404 for default. I guess I will have to check back later ;)
I have more computer vision APIs to try. Stay tuned!
I’ve been actively looking at machine learning lately. Fascinating applications in day to day live! Often unexpected. Always amazing. More and more accessible every day. Google’s Motion Stills blew me away the other day. Classification of motion vectors and biased estimation models (in a temporal consistent manner, no less) - a lot of science and novel ideas in a free consumer mobile app. Enabled and powered by machine learning.
You have probably noticed a new breed of APIs popping up all over the web. Some simply call it Machine Learning APIs, others call it Cognitive Services, some simply call it Watson. Pre-trained models operationalized with an API layer and APIs to train your own.
This blog post series offers you a short tour of these new machine learning powered APIs. I am going to start with Vision and today I am tasting Microsoft Cogntive Services (aka Project Oxford).
Setup
I am going to use JavaScript and my browser. These are all HTTP APIs so I should be able to just talk to them with very little overhead or ceremonies. Besides, since the intent is to taste (and test) the APIs, I figured I would also take the latest JavaScript and browser APIs for a spin. No transpilation. No polyfills. No external dependencies. Hence a fair warning: the examples are likely to only work in latest evergreen browsers. I am using connect serve-static as my web server (here’s how).
Let’s see how much a computer vision can see in my avatar.
Describe
According to the documentation, the Describe endpoint generates a description of an image in human readable language with complete sentences. The description is based on a collection of content tags, which are also returned by the operation.
Getting started is just a few clicks and API reference is very transparent. Here we go:
Very straightforward with no surprises. Everything just worked. Here’s what the Describe API sees in my avatar:
A man holding a cell phone (19% confidence) A man holding a phone (17% confidence) A young man holding a cell phone (12% confidence)
It definitely sees a man. It’s not sure whether a man is young. It probably doesn’t know what a microphone is but it vaguely remembers that phones used to look like this:
Another API endpoint can report tags and also provide the level of confidence in each. I sent the same request to /vision/v1.0/tag and here’s what I got back:
person (100%) man (95%) indoor (94%) microphone (22%)
I wonder why microphone wasn’t detected by the Describe endpoint. I would expect that Describe gets the tags from Tag and then uses language generation algorytms to build the description. Apparently not.
Analyze
One more API endpoint that can process an image from many angles at once. It will report the most likely description and will send down the tags. You can also ask it to detect faces and more. I asked for Description, Tags, and Categories. This one does feel like an aggregation. I got the same set of tags as I got from Tags, same most likely description (with a cell phone) and a longer list of tags as I got from Describe. The category was identified as:
people_young with 81% confidence
Summary
Microsoft Vision API allows you to see one image at a time. You can either upload the binary or point it at a publicly accessible URL. Depending on what you’re after you can get different results. I am still puzzled by the difference in reported tags. It’s capable of working with domain models to do more specialized detection but right now has only one trained - celebrities. I am sure Microsoft will deploy more and will likely let you train your own. I don’t know when but I know that there are other vision APIs that do so.
I have not been actively hands-on with Sitecore lately. But once in a while I come across a question that sounds like a good puzzle to roll up my sleeves for, and then I just can’t help it.
Query
One of our engineers posted a question. Their client’s CM instance was running noticabely slow and the users were complaining. They quicky identified the bottleneck with the SQL profiler but the finding puzzled them:
IF EXISTS (SELECTNULL FROM [SharedFields] WITH (NOLOCK) WHERE [SharedFields].[Value] LIKE@blobId) BEGIN SELECT1 END ELSE IF EXISTS (SELECTNULL FROM [VersionedFields] WITH (NOLOCK) WHERE [VersionedFields].[Value] LIKE@blobId) BEGIN SELECT1 END ELSE IF EXISTS (SELECTNULL FROM [ArchivedFields] WITH (NOLOCK) WHERE [ArchivedFields].[Value] LIKE@blobId) BEGIN SELECT1 END ELSE IF EXISTS (SELECTNULL FROM [UnversionedFields] WITH (NOLOCK) WHERE [UnversionedFields].[Value] LIKE@blobId) BEGIN SELECT1 END
Who Are You
I have once traversed basic item APIs all the way down to data providers and back so I just knew where to look. SqlServerDataProvider in Sitecore.Kernel has a method with a very telling name that runs this query.
The name of the method is - GetCheckIfBlobShouldBeDeletedSql(). Walking up the usages chain I found who runs it:
Every item save will call RemoveOldBlobs() that will end up running the mentioned SQL query if RemoveUnusedBlobsOnSave is set to true.
The method runs asynchronously so it doesn’t directly impact the executing thread, but it does put pressure onto the SQL server. Running LIKE logic looking for GUIDs (even without %) in a non-indexed nvarchar field across mutliple tables will take some cycles.
Recommendation
It’s good that this logic is protected with a feature toggle.
I suggested that the team turns off Settings.RemoveUnusedBlobsOnSave and contacts Sitecore Support.
This behavior was observed in 8.1 Update 2. I opened 8.0 Initial Release just out of curiosity and SaveItem() doesn’t go looking for old BLOBs. I didn’t go through more recent releases but it has got to be a relatively new addition. Probably added for a reason.
If we turn off running it on every item save, when should we run it? Maybe it’s missing the ID of the saved item in the WHERE to make it a lot more specific? Don’t know. I will update this post if/when we hear back from the support team.
In part 1 of this series I made an argument that Sitecore needs a new field type that would support workflow and versioning without adding language variance. Let’s see why.
Presentation
Presentation details were Shared in older versions of Sitecore . It means no versioning, no workflow support, and no language variance. A page item under workflow will not publish its latest version until the workflow reaches the final state. Too bad for the Shared fields though. Once modified, the change will be picked up by the smart or full publish. A threat is very much real - just like I hope you are using workflows, I also hope that you are using scheduled publishing agents and don’t let your authors work as admins.
Versioned Layouts
Sitecore 8 introduced versioned layouts. Presentation details can now be both Shared and Final and the end result is merged at run time. The promise of versioned layouts is to workflow-enable the presentation details and to also allow language variance. The problem is - you can’t get one without the other.
One Language
I stand corrected. You actually can have workflow support without language variance. Just don’t translate your content. If your site only supports one language, you’ll enjoy using versioned layouts. I would even suggest that you forego the good old __Renderings (Shared layout) altogether to ensure proper versioning and workflow support of your presentation. Rejoice!
Multilingual
There are more than one way to build a multilingual site in Sitecore. Previously, if your layout was the same across languages you could safely translate a single content tree. Now you can do even more with a single content tree thanks to version layouts that can easily accommodate certain language variances. If the content varies significantly and translated sites feel more like distinct online properties, you will probably build parallel content structures but let’s focus on a more common example.
Single content tree. Translated. Under a workflow. Scheduled publishing agents. Best practices. Right?
A change to the Shared portion of the layout is susceptible to the same accidental publishing as the entire layout in older version of Sitecore.
Understood. Can we use final layouts?
A change to the Versioned portion of the layout, while workflow controlled and versioned, only affects a single language.
Wait a minute. Can I or can I not safely and soundly workflow control my layout?
The answer is - it depends. If your presentation details are exactly the same across all translations, then you probably can. You will need language fallback and a little discipline. Language fallback will propagate the value from one language to another provided that the value in another language is null. An empty layout is not null (try resetting it and look at the raw value if you wonder what it is) so there goes the first wrinkle. Any accidental (or not) change to the layout in Experience Editor done not in context of the primary language will break the fallback chain.
Tough. And what if you have a layout variance in a given language?
The Missing Field Type
Well, like I said, Sitecore needs another field type - Workflowed. And I wouldn’t worry about migration issues to be honest. One of the recent updates changed the way clones are handled. A breaking change indeed. Migration instructions included a simple SQL script to upmigrate all clones. Easy, no big deal. Same could be done to legacy __Renderings if field type changed from Shared to a new Workflowed.
Call your congressman.
Something occurred to me while I was writing this small series. There is another best practice that has a very complicated relationship with the workflow. We embrace it and bet our content architectures on it and yet it gets in a way of a smooth and predictable editorial process. Datasorces. Why is it? Can something be done about it?
Next time on this blog. Stay tuned!
p.s. You can also account for language variance in a layout with personalization by language but I would probably advise against it. Assuming, of course, that you are using marketing automation capabilities of Sitecore and specifically the A/B content testing. Algorithms that generate multivariate permutations and track test performance can’t tell the difference between a functional personalization and a marketing-driven experience variance. Hopefully I get to write about it some time later.
If you haven’t read my post from last year about Sitecore’s Items, Fields, Versions, and Languages I would recommend that you do it first. In this post i will make an argument that Shared, Unversioned, and Versioned is not enough and we need another field type - Workflowed. Even if only for one particular field.
Shared
Shared fields are very basic. Value of a shared field has no language variance and no history. It cannot be workflow controlled and it cannot be restored to a previous value. You probably rarely use them on content items managed by the authoring teams exactly for the reasons outlined. You will find them, however, on the Standard Template and throughout the Sitecore internals in general.
Things that are inherently global and stable, things that an item either has or doesn’t have, things that never vary across translations, things that don’t change how an item is rendered - these are the qualities of a shared field. Good examples - __Is Bucket and __Enforce version presence. Bad example - __Renderings.
Unversioned
Unversioned fields are rare these days. Value of an unversioned field will differ across translations but it still has no history and no workflow support. Same qualities as Shared basically plus a per-language variance. An attribute of an item has to be textual or otherwise different per language and yet be global and stable to warrant an unversioned field. Good example - __Short description from the Help section.
Versioned
The bread and butter of content items. Supports language translation, has history, and is subject to a workflow. What’s not to like? The majority of the fields you create should be versioned. Well, at least they should have history and workflow support and what other choice you have then, right?
Having both language and version angles can sometimes produce friction. You can have former without the latter (the Unversioned fields) but not the other way around. If you need history and workflow - and you do almost always need it - you have to also deal with the fact that each language translation has its own value.
Workflowed
I feel that we need one more field type. Unversioned fields add the language (translation) dimension to the Shared fields. Versioned fields add the version (history and workflow) dimension to the Unversioned fields. What if I wanted history and workflow support without language variance? What if there was a Workflowed field type that was subject to a workflow and supported history rollbacks but didn’t have the language angle? Basically, a version dimension added to the Shared fields.
A field without a language angle represents something that is the same across all translations. If you use Shared field type you subject yourself to accidental publishing of new values while everything versioned is still in the draft state. If you use Versioned field type you have to maintain the same value for all translations contract.
Why is it a problem? Next time on this blog. Stay tuned for Part 2.
Do you have a dedicated devops person on your team? Maybe you have a shared team of devops engineers? Do you hire for devops role and build centers of excellence (CoE) around it? These engineers are responsible for environment provisioning and builds, they create and maintain your CI/CD pipelines, they chose a specialization in Chef or PowerShell DSC or Gradle? If you are Rackspace or a Rackspace-wannabe, then you’re probably on the right track. And if you are not then I don’t think you are doing it right.
A dedicated DevOps role is basically ops co-located with devs. It’s a lot better than old school functional structure with ops and devs isolated but it’s not yet the DevOps nirvana.
Let’s make a step back for a second. What are we trying to achieve? Use the modern infrastructure-as-code toolset? Be more agile in the operational aspects? Deliver continuously? Or maybe we also want shared responsibility? Devs thinking about Ops concerns (migration, monitoring, scalability, automation, instrumentation, upgrades, business continuity) when writing code and designing systems, not after? Not just deliver continuously but do so with confidence? Maybe we also want to better our dev teams? Make them not only full stack but also cross stack?
Expose your dev teams to ops concerns. Make them orchestrate provisioning and automate builds. Make them monitor and instrument their deployments. Have them learn some Chef, Shell, Powershell, Gradle, Buildr, Capistrano, Whathaveyou. It will only make better technologists out of them. Dedicate ops to run the underlying stacks (the vSpheres, and Swarms, and Kuberneteses of the world), to expose custom infrastructure concerns as code, to maintain an ever-growing repository of scripts and images and containers, to establish best practices. Using it should be part of the dev role.
What doesn’t kill you makes you stronger. Or so it should.