DNS as your Edge database
Modern computing has gone a long way. Elastic architectures have become commodities. With platforms like AWS and all its serverless offerings, you can build very reliable and very scalable systems. We learned to push static content very close to the end users thanks to the proliferation of CDNs. We then learned to run compute at the edge as well. One thing we still can’t really do effectively is push data to the edge.
What if I told you that you could use DNS? I didn’t come up with the idea. I’ve read about it here some time ago and when I had a problem that sounded like - “how do I get my data closer to the edge” - I remembered that blog post and I decided to try and do it.
An important caveat first. The problem I was solving is not a typical OLTP data problem. You are very unlikely to actually be able to replace a database with DNS using the approach I will present here. You can, however, deliver a fairly stable (and fairly small) dataset to the edge ang have low single to double digit milliseconds response time reading the data from anywhere in the world.
The Problem
One of the services that we built as part of the ecosystem that powers EPAM Anywhere exposes various reference data using REST APIs. It’s a story for another day, but we have a large data platform underpinning a lot of different applications. You can connect to the firehose of data by listening to the individual Kafka topics that interest you. If you need a simple search-as-you-type access though, we have a simple fast reliable and elastic REST API for you. Think of it as kafka -> elastic -> lambda -> edge cache -> (You).
Some of these APIs are public. The data they expose is not confidential and is needed by various apps in our ecosystem. Things like our skill taxonomy and the world’s database of geographical locations like countries and cities. Access to all APIs is auth-protected. All privileged APIs require that you come with a valid JWT token from our SSO IDP. Public APIs do a simple api key authentication similar to that of Google APIs. All keys are CORS-enabled for the specific domains that you register for your app. It’s a soft protection plus it allows us to track the usage by client.
We aggressively cache API responses that don’t work with volatile data and would like to guarantee sub-half-second response time on “cold” queries and double digit ms when you access what’s been cached. All our APIs are fronted with CloudFront so we cache at the edge. And here goes the problem.
How can we check the API key efficiently at the edge before we look up the cached response?:
Options
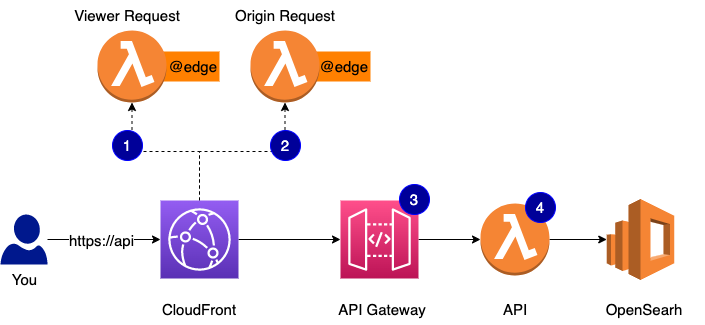
First, let’s talk about caching of your API responses. You have a number of options and I will rate them from more difficult/custom to more easy/out-of-the-box.
- You can build the cache yourself. Have every request go all the way through to your API function (#4 on the diagram) and have it pull the response from the cache.
- You can have the cache done at the API Gateway level. That would be #3 on the diagram. AWS has two API Gateway products - REST API and HTTP API. We are using HTTP API for everything that doesn’t need special networking setup. HTTP API doesn’t have a cache built-in. REST API does but it really is a provisioned instance. You can read more here.
- You can cache at the edge using CloudFront cache behavior. This cache is the simplest to set up and would be the closest to your users no matter where they are in the world.
I really like the last option and that’s how we cache most of the time. It does create an interesting problem though for APIs that require authentication.
Take a look at the diagram above. When you make a GET HTTP API request and I already have a response cached for you, the request won’t ever go past #1. CloudFront allows you to run compute in response to certain events. Here is a very good summary if you are new to the concept. Every request, no matter if it’s cached or not and if a cached response is available, will trigger viewer-request function. After that, if you have the cached response, CloudFront will turn around, call viewer-response if you have one configured, and never talk to the origin. The problem is:
How do we validate that API access was authorized?
The only option we have if we chose to use CloudFront as a cache provider and require that API requests be authenticated is to run auth in the viewer-request function. This function will run in the AWS region closest to the user. This is how lambda@edge works. You can get closer and run in actual edge locations with CloudFront Functions but these awesome compute units can actually do very little. The region closest to the user is close enough, I think, but we still have a problem:
How do we ensure that key validation is as fast as possible?
We manage all API keys and all metadata about them - what APIs a key has access to, its CORS configuration, etc. - in a DynamoDB table. The table is in one region. The lambda@edge may run in the same region or may run on the other side of the world. This roundtrip can add several hundreds of milliseconds latency just to check if a key is valid. And then if we have nothing in the cache for the authenticated request, we will do another round trip to get the payload.
And that’s how I thought to try Route 53 as a delivery mechanism of the API key metadata.
Architecture
At a glance, the architecture looks like this:
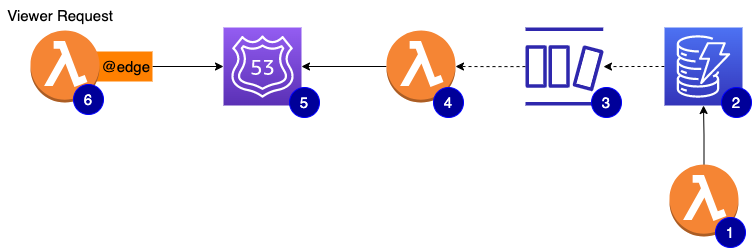
- #1 is a lambda function that is basically a CRUD API used by our developer portal to provision and manage your API access
- #2 is the main DynamoDB table. The source of record for all API keys metadata
- #3 is the stream enabled on the DynamoDB table to stream out any changes
- #4 is a lambda function subscribed to the stream. Depending on the event captured, it will create, update, or delete a DNS replica using one
TXTrecord per key - #5 the
viewer-requestcan nowdigDNS TXT record to quickly check if the API key is valid and has access to the requested API
Say you have your API on api.yourdomain.com and you have an API key for the said API - dfe1d217-21ce-4fc3-b6b1-c12b6a4740dc. Take some salt and some MD5 and your key becomes AB7F79C51610E78C7B1AD9EB4F8409A9. Take that and create a TXT record of AB7F79C51610E78C7B1AD9EB4F8409A9.api.yourdomain.com with the string value of serialized JSON with the key metadata. You can salt + md5 that as well just in case. I know that MD5 is a poor choice for passwords and the like (more here) but we are not talking strong cryptographic security here. Plus, even if you know the api.yourdomain.com, you can’t really query all its TXT records to go and brute-force-decode the actual API keys out of them. You can only dig a particular fully qualified DNS record.
In Action
And now, having built the replication of the key metadata to DNS, we can inspect a given API key in runtime using a simple DNS dig. The process is basically a reverse of replicating the key.
You do:
1 | $ curl -H 'x-api-key: dfe1d217-21ce-4fc3-b6b1-c12b6a4740dc' https://api.yourdomain.com/myapi/data |
The viewer-request function takes the x-api-key, applies the known salt with MD5, does the DNS dig for AB7F79C51610E78C7B1AD9EB4F8409A9.api.yourdomain.com and knows if your key is valid and what APIs it has access to.
Here’s how it looks in Typescript:
1 | import * as dns from 'dns'; |
Limitations
One important limit that I need to tell you about is 10,000 records in a hosted zone for Route 53. You can add more, but additional charges will apply. You can read more here. Like I said - a fairly stable and a fairly small dataset :)
Till next time!
