Content Work Automation with Text Analytics API
In my last post I used Computer Vision APIs to automate image tagging. Let’s see if machine learning APIs can help us automate tedious content work like SEO keywords generation and text proof reading.
Microsoft Cognitive Services offers Text Analytics API that can extract keywords from text and can also do sentiment analysis. I will again use Sitecore, its Habitat demo site, and Powershell Extensions to automate everything though the concepts should apply to any modern CMS.
Key Phrases
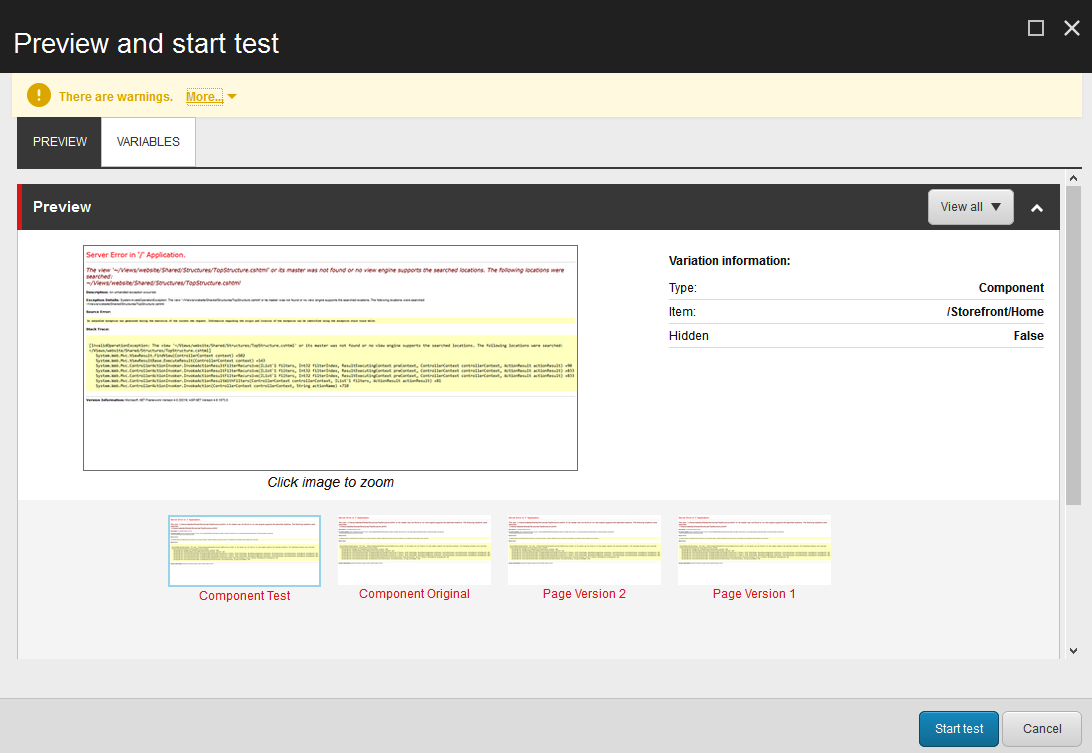
It’s probably not hard to come up with a decent list of keywords for a body of text that is a web page. As the size of your site grows, however, the task becomes very tedious very quickly if performed manually. Add to that the editorial calendar with frequent updates and you now run a risk of having obsolete keywords adversely impacting your SEO. Add to that a component based approach with proper content reuse and flexibility in the hands of your content teams and it’s even harder to track what exactly each page renders on the live site. Everything that can be automated should be automated,
Getting keywords for a given text fragment from Text Analytics API is very straightforward:
1 | $keywords = Invoke-WebRequest ` |
Here’s how I am going to aggregate the content for a given page:
1 | function GetContent($item, $layout = $False) |
Basically, I will get various content fragments concatenated together into one big blob of text.
Aggregating Content
The GetContent function will get all content fields off of the item and then will recursively process all the datasources that the layout references. It’s actually smart enough to also resolve links to other items like you would find in the content fields on the carousel panels, for example. It will go as deep as needed, will strip out rich text markup, will skip system fields, and will even handle cyclic references.
Take a look on github if you’re interested, I enjoyed writing this one.
Keywords That Matter
For my experiment I decided to limit the key phrases returned by the API to only those that have words capitalized. I figured it’s a good indication of a header or a subtitle plus it helps spot ALL CAPS text as you will see in a minute:
1 | $keywords.documents[0].keyPhrases ` |
Here are the results for the home page, for example. You probably would want to exclude things that you know are not your keywords (e.g. Search Resutls, Tweets):
1 | The text is 100.0% positive |
Proof Reading
Text Analytics can also tell you how positive your text sounds. positivity is measured in percentage points from 0% to 100%. It’s also just one HTTP request away if you have your text readily available:
1 | $sentiment = Invoke-WebRequest ` |
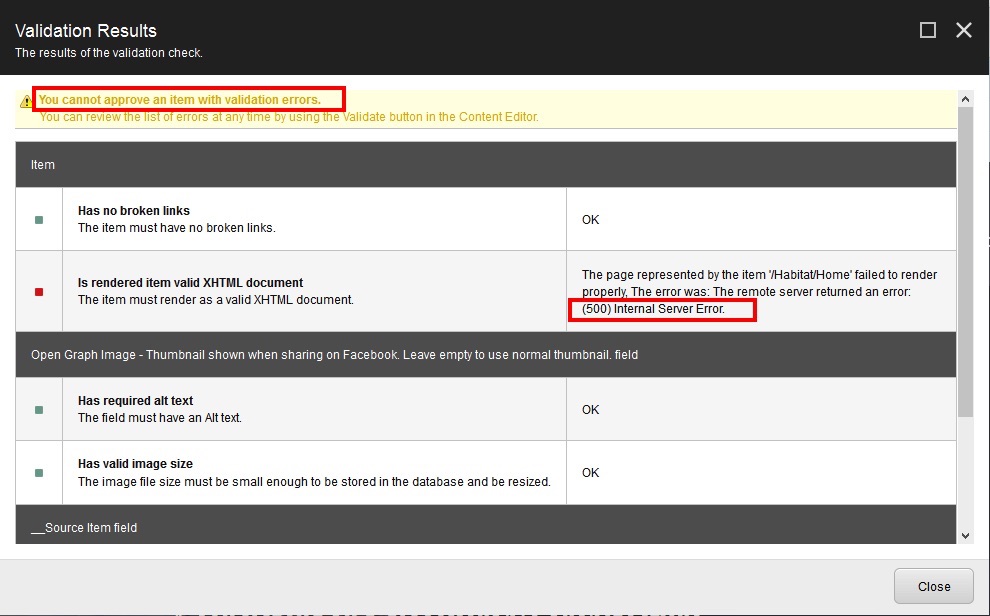
Many pages in the Habitat demo site are close to 100% positive. That’s to be expected for the elevated marketing speak I guess. A few, however, came back with just 16%. And it turns out that you don’t have to sound too negative to score that low. It’s enough to just be very dry and matter-of-factly. Like this:
1 | The accounts module handles user accounts and user profiles including login, registration, forgot password and profile editing. |
Imagine running a script like that for all the pages on your site and sending the results off to your content team? Maybe you will not be able to completely automate keywords generation but you will definitely help them spot content that needs improving.
I have been working with cognitive APIs for a while now and I am still surprised how easy it is to get stuff done. I am even more excited about what’s coming in the near future! So much so that I will be speaking about cognitive APIs and smart apps that one can built with them on the API Strategy conference this coming November. See you in Boston!