Image Tagging Automation with Computer Vision
I have recently presented my explorations of computer vision APIs(part 1, part 2, and part 3) on the AI meetup in Alpharetta. This time I decided to do something useful with it.
Image Tagging
When you work with digital platforms (be that content management, e-commerce, or digital assets) you can’t go far without organizing your images. Tagging makes your assets library navigable and searchable. Descriptions are a great companion to the visual preview and can also serve as the alternate text. WCAG 2.0 requires non-text content to come with a text alternative for the very basic Level A compliance.
Computer Vision
When I played with the trained computer vision models from different vendors, I realized that I can get a good set of tags from either one of the APIs and some would even try to build a description for me. The digital assets management vendors started playing with this idea as well. Adobe, for example, has introduced smart tags in the latest release of AEM. Maybe I can do the same using Computer Vision APIs and integrate with a digital product that doesn’t have that capability built in yet? Let’s try with Sitecore.
Automation
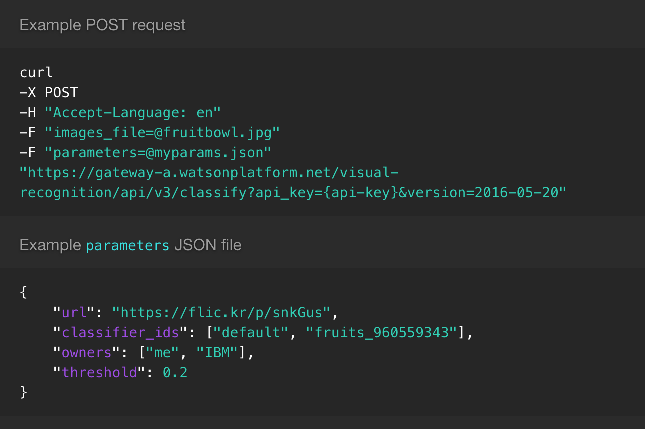
I am going to use Computer Vision from Microsoft Cognitive Services and the Habitat demo site from Sitecore. I am also going to need Powershell Extensions to automate everything.
We will need the URL of the computer vision API, the binary array of the image, the Sitecore item representing the image to record the results on, and a little bit of Powershell magic to glue it all together.
Here’s the crux of the script where I call into the computer vision API:
1 | $vision = 'https://api.projectoxford.ai/vision/v1.0/analyze' |
It’s that simple. The rest of it is using Sitecore APIs to read the image, update the item with tags and descriptions received from the cognitive services, and also a try/catch/retry loop to handle the API’s rate limit (in preview it’s limited to 5000/month and 20/minute). You can find the full script on github.
20/20
Some images were perfectly deciphered by the computer vision API as you can see in this example (the %% are the confidence level reported by the API):

Legally Blind
But some others would puzzle the model quite a bit:

Not only there’s no Shu Qi in the picture above, there’s definitely no hot dog and no other food items. Granted, the API did tell me that it was not really sure about what it could see. Probably a good idea to route images like that through a human workflow for tags and description validation and correction.
Domain Specific Models
The problem with seeing the wrong things or not seeing the right things in a perfectly focused and lit image is … lack of training. Think about it. There are millions and millions of things that your vision can recognize. But you have been training it all your life and the labeled examples keep coming in on a daily basis. It takes a whole lot of labeled images to train a generic computer vision model and it also takes time.
You can get better results with domain specific models like that offered by Clarifai, for example. As of the time of this writing you can subscribe to Wedding, Travel, and Food models.

I am sure you’ll get better classification results out of these models than out of a generic computer vision model if your business is in one of these industries.
Next time I will explore Text Analytics API and will show you how it can help tag and generate keywords for your content.